About
The ACM RecSys Challenge 2017 is focussing on the problem of job recommendations on XING in a cold-start scenario. The challenge will consists of two phases:
- offline evaluation: fixed historic dataset and fixed targets for which recommendations/solutions need to be computed/submitted.
- online evaluation: dynamically changing targets. Recommendations submitted by the teams will actually be rolled out in XING's live system (details about the online evaluation such as the approach for ensuring fair conditions between the teams will follow).
Both phases aim at the following task:
Task: given a new job posting p, the goal is to identify those users that (a) may be interested in receiving the job posting as a push recommendation and (b) that are also appropriate candidates for the given job.
For both offline and online evaluation, the same evaluation metrics and the same types of data sets will be used. The offline evaluation is essentially used as an entry gate to the online evaluation:
- the top teams (which also pass a XING baseline) will be allowed to participate in the online evaluation.
- Winner of RecSys Challenge 2017 = Winner of the online challenge
Recommendation Scenario top
The online evaluation focus on a push recommendation scenario in which new items (job postings) are given and users need to be identified...
- who are interested in job postings in general (e.g. open to new job offers, willing to change their job)
- who are interested in the particular job posting which they are notified about
- who are an appropriate candidate for the given job posting (e.g. recruiters who own the job postings indicate that they are interested in the candidate)
In the online challenge, teams will only submit their best user for an item to the system. For each target item users are allowed to submit one or more target users. However, each user can only be submitted once. Since push recommendations are presented to the users in a more prominent way, we decided on this restriction. These recommendations are then played out to the user over the following channels.
(p1, u42), (p1, u23), ... where pi is the i-th target posting and uj is the j-th target user, the recommendations are delivered to users through the following channels:
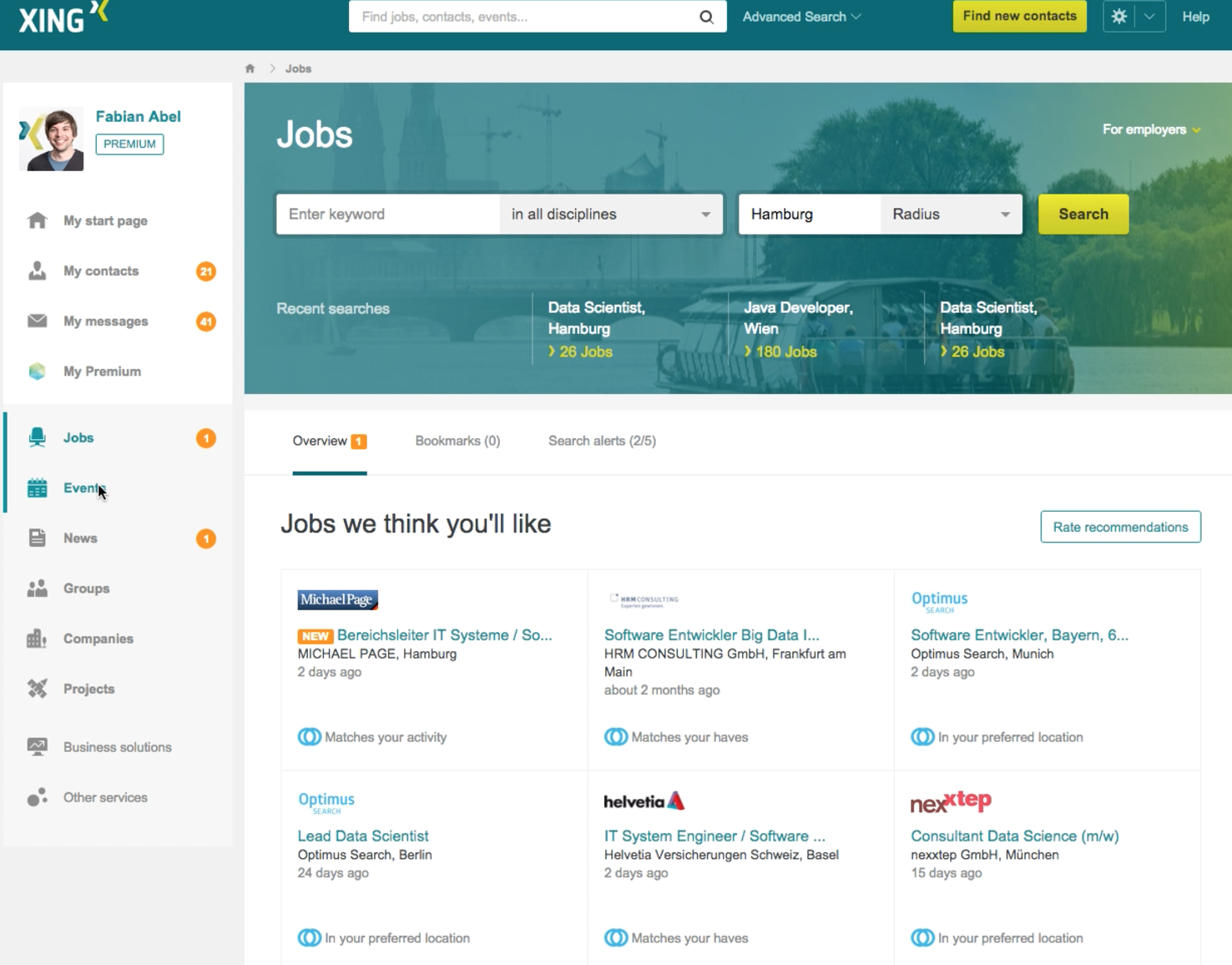
- activity stream: "Vacancies matching your profile" story in the stream on xing.com and in the mobile apps. (see screenshot)
- jobs marketplace: an orange notification bubble in the side-bar and an orange label "new" highlights the new job recommendation, e.g. on xing.com/jobs or in the mobile apps (see: screenshot)
- emails: if the user did not see the push recommendation then the user may receive an email that points him/her to the job recommendation (see screenshot)
- recruiter tools: users which receive a job posting as push recommendation are also likely to appear as candidate recommendations to recruiters, for example, in the so-called XING talent manager (see screenshot)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Challenges top
Some challenges that the participating teams will need to solve:
- Balancing user interest and recruiter demands: In contrast to last year's challenge which was solely focusing on estimating how relevant a job is for a given user, this year we will focus on both: Job recommendations should be relevant to the users and at the same time the users who receive those job recommendations also need to be appropriate candidates for the given job (e.g. the fact whether a user received interest from a given recruiter is part of the evaluation measure).
- Balancing relevance and revenue: Some of the content is paid and some users pay for subscriptions. Teams will need to balance between relevance of recommendations and monetary aspects (i.e. the money that is earned with the recommendation).
- Novelty / sparsity: recommendations need to be computed particularly for newly created job postings (those postings have not received any interaction).
- Smart targeting of push recommendations: also, teams will need to estimate how likely it is that a user is actually interested in job recommendations, e.g. users that are not interested in job recommendations may delete recommendations or disable push recommendation notifications in case they receive too many (the latter is primarily relevant for teams that participate in the online challenge).
Evaluation Metrics top
Given a list of target items targetItems, for which the recommender selects those users to whom item in T, is pushed as recommendation, we compute the the leaderboard score as follows:
score(targetItems) = targetItems.map(item => score(item, recommendations(item))).sum
Here, recommendations(item) specifies the list of users who will receive the given item as push recommendation. The function score(item, users) is defined as follows:
score(item, users) =
users.map(u => userSuccess(item,u)).sum + itemSuccess(item, users)
userSucess(item, user) =
(
if (clicked) 1 else 0
+ if (bookmarked || replied) 5 else 0
+ if (recruiter interest) 20 else 0
- if (delete only) 10 else 0
) * premiumBoost(user)
premiumBoost(user) = if (user.isPremium) 2 else 1
itemSuccess(item, users) =
if (users.filter(u => userSuccess(item, u) > 0).size >= 1) {
if (item.isPaid) 50
else 25
} else 0
Meaning:
score(item, users)sums up the success rates of the users and the item-based success rate.userSucess(item, user)scores a user-item pair based on the interactions between those items:- clicks: user clicked at least once on the pushed recommendation, i.e. multiple clicks won't increase the points (1 point)
- bookmarks/replies: the user bookmarked the item or clicked on the reply button (which guides the user to the application form of the job posting) (5 points)
- recruiter interest: a recruiter who owns the item showed interest into the user (e.g. clicked on the profile) for the given job item (20 points)
- deletes: in case we solely observed that the user delted the item (no click, no bookmark/reply, no recruiter interest), we count the pushed recommendation as negative feedback (-10 points)
premiumBoost(user)userSuccess scores count double points for premium users.itemSuccess(item, users)if at least one successful push recommendation was created for a given item then this counts 50 points for paid items and 25 for other items.
Purpose of evaluation metrics:
- both user satisfaction and the success from an item (aka recruiter) perspective is taken into account
- satisfied (and dissatisfied) premium users have a stronger impact than basic users.
- paid content is promoted compared to non-paid content
The above evaluation metrics will be applied for both offline evaluation and online evaluation (in the offline evaluation, the target items won't change during the challenge while in the online evaluation, new target items are relased on a daily basis).
Dataset top
The training dataset is supposed to be used for experimenting and training your models. You can split the interaction data into training and test data. For example: you can leave out the last complete week from the interaction data and then try to predict whether for a given job posting, you can predict the users that will positively interact with the posting.
Anonymization, pseudonymization, noise top
The training dataset is a semi-synthetic sample of XING's dataset, i.e. it is not complete and enriched with noise in order anonymize the data. For example:
- the dataset contains artifical users
- the dataset contains only a fraction of XING users and job postings
- IDs are used instead of raw text for almost all attribute values (pseudonymization)
- some attributes of the users may have been removed or flipped to NULL / unknown.
- not all interactions of a user are contained in the dataset
- some of the interactions are artificial (= have actually not been performed by the user)
- timestamps have been shifted (but the order of interactions is kept)
Attempting to identify users or to reveal any private information about the users or information about the business from which the data is coming from is strictly forbidden (cf. Rules).
Interactions top
interactions.csv: Interactions are all transactions between a user and an item including recruiter interests as well as impressions. Fields:
user_idID of the user who performed the interaction (points tousers.id)item_idID of the item on which the interaction was performed (points toitems.id)created_ata unix time stamp timestamp representing the time when the interaction got createdinteraction_typethe type of interaction that was performed on the item:- 0 = XING showed this item to a user (= impression)
- 1 = the user clicked on the item
- 2 = the user bookmarked the item on XING
- 3 = the user clicked on the reply button or application form button that is shown on some job postings
- 4 = the user deleted a recommendation from his/her list of recommendation (clicking on "x") which has the effect that the recommendation will no longer been shown to the user and that a new recommendation item will be loaded and displayed to the user
- 5 = a recruiter from the items company showed interest into the user. (e.g. clicked on the profile)
Users top
users.csv: Details about those users who appear in the above datasets. Fields:
idanonymized ID of the user (referenced asuser_idin the other datasets above)jobrolescomma-separated list of jobrole terms (numeric IDs) that were extracted from the user's current job titlescareer_levelcareer level ID (e.g. beginner, experienced, manager):- 0 = unknown
- 1 = Student/Intern
- 2 = Entry Level (Beginner)
- 3 = Professional/Experienced
- 4 = Manager (Manager/Supervisor)
- 5 = Executive (VP, SVP, etc.)
- 6 = Senior Executive (CEO, CFO, President)
discipline_idanonymized IDs represent disciplines such as "Consulting", "HR", etc.industry_idanonymized IDs represent industries such as "Internet", "Automotive", "Finance", etc.countrydescribes the country in which the user is currently working- de = Germany
- at = Austria
- ch = Switzerland
- non dach = non of the above countries
regionis specified for some users who have as countryde. Meaning of the regions see belowexperience_n_entries_classidentifies the number of CV entries that the user has listed as work experiences- 0 = no entries
- 1 = 1
- 2 entries
- 2 = 3
- 4 entries
- 3 = 5 or more entries
experience_years_experienceis the estimated number of years of work experience that the user has- 0 = unknown
- 1 = less than 1 year
- 2 = 1 - 3 years
- 3 = 3 - 5 years
- 4 = 5 - 10 years
- 5 = 10 - 20 years
- 6 = more than 20 years
experience_years_in_currentis the estimated number of years that the user is already working in her current job. Meaning of numbers: same asexperience_years_experienceedu_degreeestimated university degree of the user- 0 or NULL = unknown
- 1 = bachelor
- 2 = master
- 3 = phd
edu_fieldofstudiescomma- separated fields of studies that the user studied.
0means "unknown" andedu_fieldofstudies > 0entries refer to broad field of studies such as Engineering, Economics and Legal, ... wtcjan estimation regarding the user's willingness to change jobs- 0 XING predicts the user has a low interest of changing her job soon
- 1 XING predicts the user has a high interest in changing her current position
premiumthe user subscribed to XING's payed premium membership- 0 no subscription
- 1 active subscription
Items top
items.csv: Details about the job postings that were and should be recommended to the users.
idanonymized ID of the item (referenced asitem_idin the other datasets above)industry_idanonymized IDs represent industries such as "Internet", "Automotive", "Finance", etc.discipline_idanonymized IDs represent disciplines such as "Consulting", "HR", etc.is_paid(oris_payed) indicates that the posting is a paid for by a compnaycareer_levelcareer level ID (e.g. beginner, experienced, manager)- 0 = unknown
- 1 = Student/Intern
- 2 = Entry Level (Beginner)
- 3 = Professional/Experienced
- 4 = Manager (Manager/Supervisor)
- 5 = Executive (VP, SVP, etc.)
- 6 = Senior Executive (CEO, CFO, President)
countrycode of the country in which the job is offeredlatitudelatitude information (rounded to ca. 10km)longitudelongitude information (rounded to ca. 10km)regionis specified for some users who have as country `de`. Meaning of the regions: see below.employmentthe type of emploment- 0 = unknown
- 1 = full-time
- 2 = part-time
- 3 = freelancer
- 4 = intern
- 5 = voluntary
created_ata unix time stamp timestamp representing the time when the interaction got createdtitleconcepts that have been extracted from the job title of the job posting (numeric IDs)tagsconcepts that have been extracted from the tags, skills or company name
Targets top
The dataset contains two additional files that contain target item IDs and target user IDs:
- targetItems.csv: contains the list of item IDs (items.id) for which recommendations should be computed and submitted.
- targetUsers.csv: set of user IDs (users.id) which are allowed to appear in the recommendations/solutions that are submited. Hence, recommending an item to users that are not in targetUsers.csv will not gain any points during the offline challenge.
Note: solutions that are submitted are only allowed to conatin items and users from the above files.
Baseline top
The baseline is using xgboost and is solely content-based. Details about the baseline and Python code are available at: github.com/recsyschallenge/2017/baseline/
Participation top
For participating in the challenge, you will need to...
- login with your XING account to the submisson system: recsys.xing.com
- create a team
- accept the rules of the challenge (fair play, don't be evil)
- wait for approval (you will receive a XING message once your team has been approved)
- download the data and get started...
Leaderboard top
The public leaderboard is based on a 30% random sample of the entire ground truth. See: recsys.xing.com/leaders
Rules top
Data
Datasets that are released as part of the RecSys challenge are semi-synthetic, non-complete samples, i.e. XING data is sampled and enriched with noise. Regarding the released datasets, participants have to stick to the following rules:
- Attempting to identify users or to reveal any private information about the users or information about the business from which the data is coming from is strictly forbidden.
- It is strictly forbidden to share the datasets with others.
- It is not allowed to use the data for commercial purposes.
- The data may only be used for academic purposes.
- It is not allowed to use the data in any way that harms XING or XING's customers.
Licence of the data: All rights are reserved by XING AG.
Final Paper
Each team should submit a paper describing the algorithms that they developed for the task (see paper submissions & workshop). Teams without a paper submission to the RecSys Challenge workshop will be removed from the final leaderboard.
No Crawling on XING
It is not allowed to crawl additional information from XING (e.g. via XING's APIs or by scraping details from XING pages).
L’esprit sportif / Fair-play
Please stick to the rules above, only sign-up for one team and stick to the submission limits: you can upload at maximum 20 solutions per day (for the offline challenge). We may suspend a team from the challenge if we get the impression that the team is not playing fair.
Ask us
If you are unsure of whether something is allowed or not, contact us (e.g. create an issue on github) and we will be happy to help you. Above all remember it's all for science, so be creative, not evil!
Questions top
Questions and remarks about the procedure and other aspects concerning the challenge can be submitted as github issues.
Prizes top
Prizes are given out to the teams that achieved the highest scores at the end of the online evaluation:
- First Team: 3000 €
- Second Team: 1500 €
- Third Team: 500 €
In order to get the prize money, teams have to describe their algorithms in an accompanying paper and present it during the RecSys Challenge workshop in Como, Italy.
Announcing Winners
Timeline top
| When? | What? |
|---|---|
| Beginning of March | RecSys challenge starts:
|
| April 16th (23:59 Hawaiian time) |
Offline evaluation ends:
|
| May 1st | Online challenge starts:
|
| June 4th (23:59 Hawaiian time) | Online evaluation ends:
|
| June 12th |
|
| June 18th | Paper submission deadline for RecSys Challenge workshop |
| July 3rd | Notifications about paper acceptance |
| July 17th | Deadline for camera-ready papers |
| August 27th-31st | Workshop will take place as part of the RecSys conference in Como, Italy. |
Workshop Program
| Time | Session |
|---|---|
| 09:00 - 10:30 |
Welcome:
|
| 10:30 - 11:00 | Coffe Break |
| 11:00 - 12:30 |
Paper presentations (20 minutes):
|
| 12:30 - 14:00 | Lunch Break |
| 14:00 - 15:30 |
Winner (20 minutes):
|
| 15:30 - 16:00 | Coffe Break |
| 16:00 - 17:30 | details will follow |
Paper Submissions & Workshop top
Each team - not only the top teams - should submit a paper that describes the algorithms that they used for solving the challenge. Those papers will be reviewed by the program committee (non-blind double review). At least one of the authors is expected to register for the RecSys Challenge workshop which will take place as part of the RecSys conference in Como, Italy.
Format top
Papers should not exceed 4-6 pages. They have to be uploaded as PDF and have to be prepared according to the standard ACM SIG proceedings format (in particular: sigconf): templates.
Upload Paper top
Papers (and later also the camera-ready versions) have to be uploaded via EasyChair: submit paper via EasyChair
Publication top
We aim to publish the accepted papers in a special volume of ACM Sig Proceedings dedicated for the challenge (cf. Proceedings of the last year: ACM, DBLP).
Program Committee top
- Farshad Bakhshandegan-Moghaddam, KIT, Germany
- Alejandro Bellogín, Universidad Autónoma de Madrid, Spain
- Matthias Braunhofer, BMW, Germany
- Ching-Wei Chen, Spotify, USA
- Mouzhi Ge, Masaryk University, Czech Republic
- Tural Gurbanov, Free University of Bozen - Bolzano, Italy
- Balasz Hidasi, Gravity R&D, Hungary
- Martha Larson, TU Delft, Netherlands
- Andreas Lommatzsch, Hungarian Academy of Sciences, Hungaria
- Pasquale Lops, University of Bari Aldo Moro, Italy
- Katja Niemann, XING AG, Germany
- Neil Rubens, Stanford University, USA
- Alan Said, University of Skövde, Sweden
- Markus Schedl, Johannes Kepler University, Austria
- Azadeh Shakery, University of Tehran, Iran
- Massimo Quadrana, Politecnico di Milano, Italy
- Hamed Zamani, University of Massachusetts Amherst, USA
- Yong Zheng, Illinois Institute of Technology, USA
Organizers top
- Fabian Abel, XING AG
- Yashar Deldjoo, Politecnico Milano
- Mehdi Elahi, Free University of Bozen-Bolzano
- Daniel Kohlsdorf, XING AG
Advisors top
- András Benczúr, Hungarian Academy of Sciences
- Róbert Pálovics, Hungarian Academy of Sciences (godfather of the challenge)
- Alan Said, University of Skövde